DPDK报文转发
基本的网络包处理主要包含:
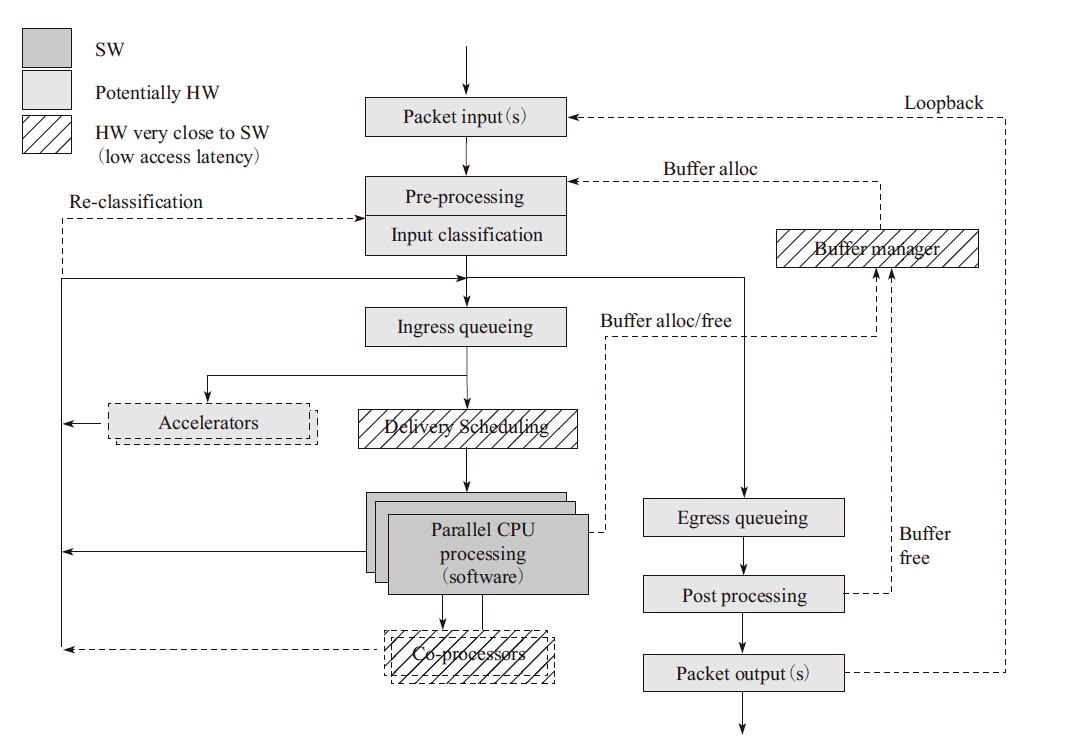
Packet input:报文输入。Pre-processing:对报文进行比较粗粒度的处理。Input classification:对报文进行较细粒度的分流。Ingress queuing:提供基于描述符的队列FIFO。Delivery/Scheduling:根据队列优先级和CPU状态进行调度。Accelerator:提供加解密和压缩/解压缩等硬件功能。Egress queueing:在出口上根据QOS等级进行调度。Post processing:后期报文处理释放缓存。Packet output:从硬件上发送出去。
专用网络处理器转发模型
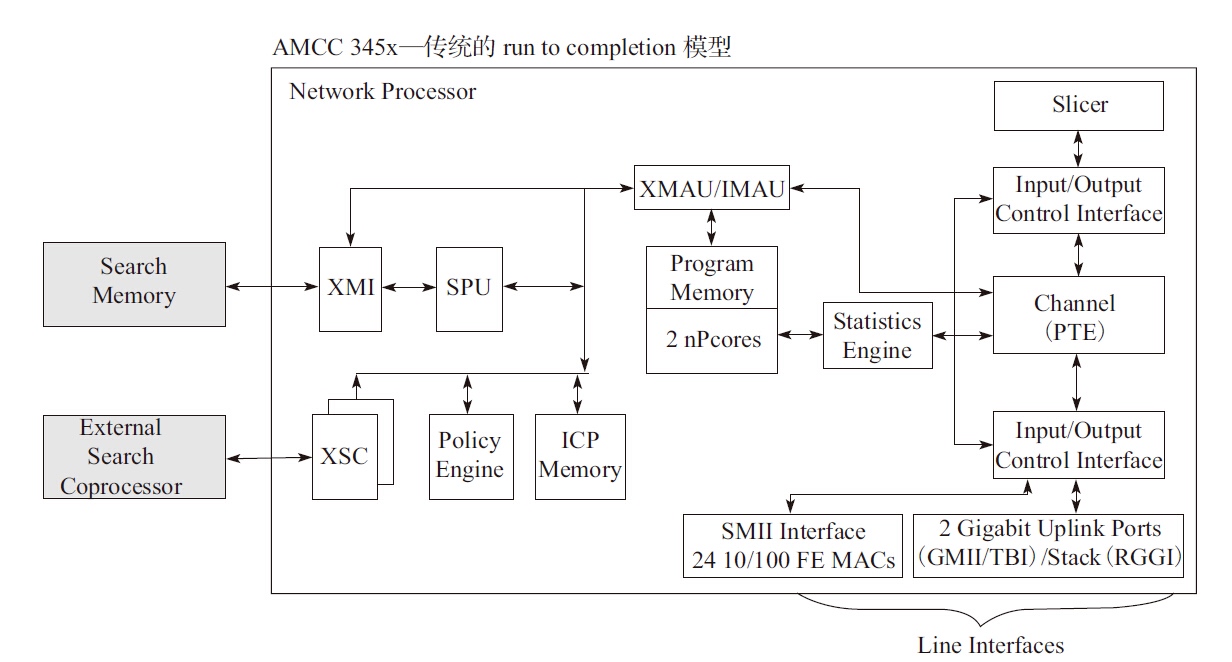
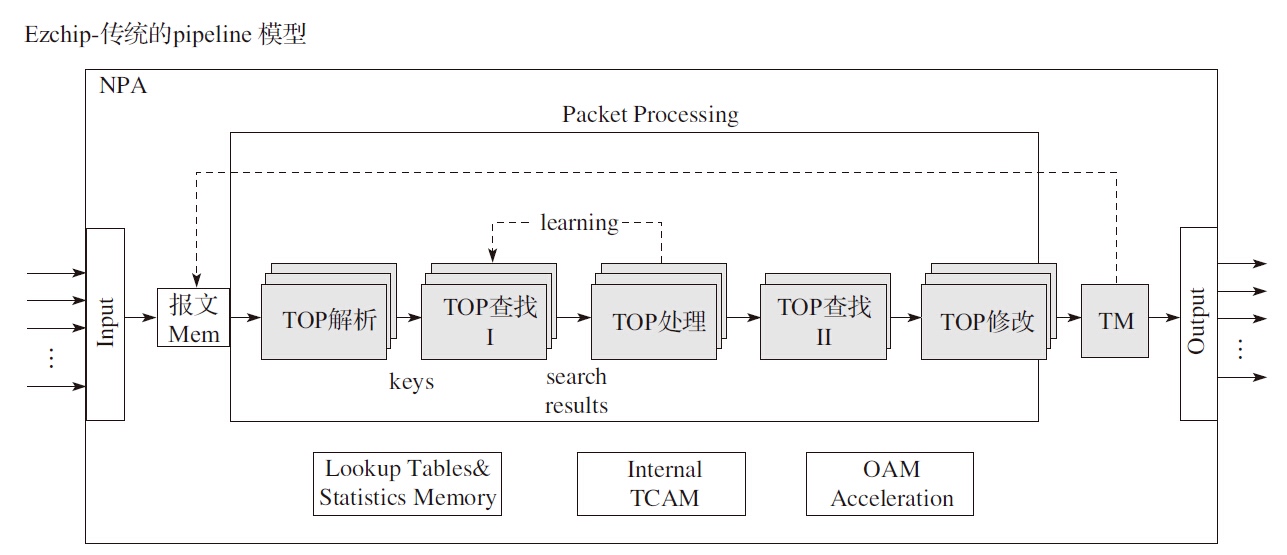
传统的Network Processor(专用网络处理器)转发的模型可以分为run to completion(运行至终结,简称RTC)模型和pipeline(流水线)模型。
DPDK转发模型
从run to completion的模型中,我们可以清楚地看出,每个IA的物理核都负责处理整个报文的生命周期从RX到TX,这点非常类似前面所提到的AMCC的nP核的作用。在pipeline模型中可以看出,报文的处理被划分成不同的逻辑功能单元A、B、C,一个报文需分别经历A、B、C三个阶段,这三个阶段的功能单元可以不止一个并且可以分布在不同的物理核上,不同的功能单元可以分布在相同的核上(也可以分布在不同的核上),从这一点可以看出,其对于模块的分类和调用比EZchip的硬件方案更加灵活。
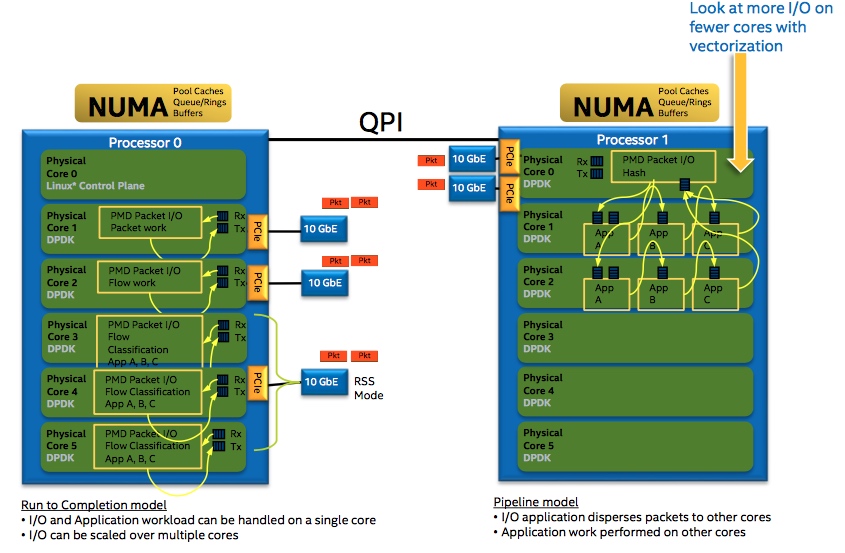

DPDK run to completion模型
在DPDK的轮询模式中主要通过一些DPDK中eal中的参数-c、-l、-l core s来设置哪些核可以被DPDK使用,最后再把处理对应收发队列的线程绑定到对应的核上。每个报文的整个生命周期都只可能在其中一个线程中出现。和普通网络处理器的run to completion的模式相比,基于IA平台的通用CPU也有不少的计算资源,比如一个socket上面可以有独立运行的16运算单元(核),每个核上面可以有两个逻辑运算单元(thread)共享物理的运算单元。而多个socket可以通过QPI总线连接在一起,这样使得每一个运算单元都可以独立地处理一个报文并且通用处理器上的编程更加简单高效,在快速开发网络功能的同时,利用硬件AES-NI、SHA-NI等特殊指令可以加速网络相关加解密和认证功能。运行到终结功能虽然有许多优势,但是针对单个报文的处理始终集中在一个逻辑单元上,无法利用其他运算单元,并且逻辑的耦合性太强,而流水线模型正好解决了以上的问题。
DPDK pipeline模型
pipeline的主要思想就是不同的工作交给不同的模块,而每一个模块都是一个处理引擎,每个处理引擎都只单独处理特定的事务,每个处理引擎都有输入和输出,通过这些输入和输出将不同的处理引擎连接起来,完成复杂的网络功能,DPDK pipeline的多处理引擎实例和每个处理引擎中的组成框图可见图5-5中两个实例的图片:zoom out(多核应用框架)和zoom in(单个流水线模块)。
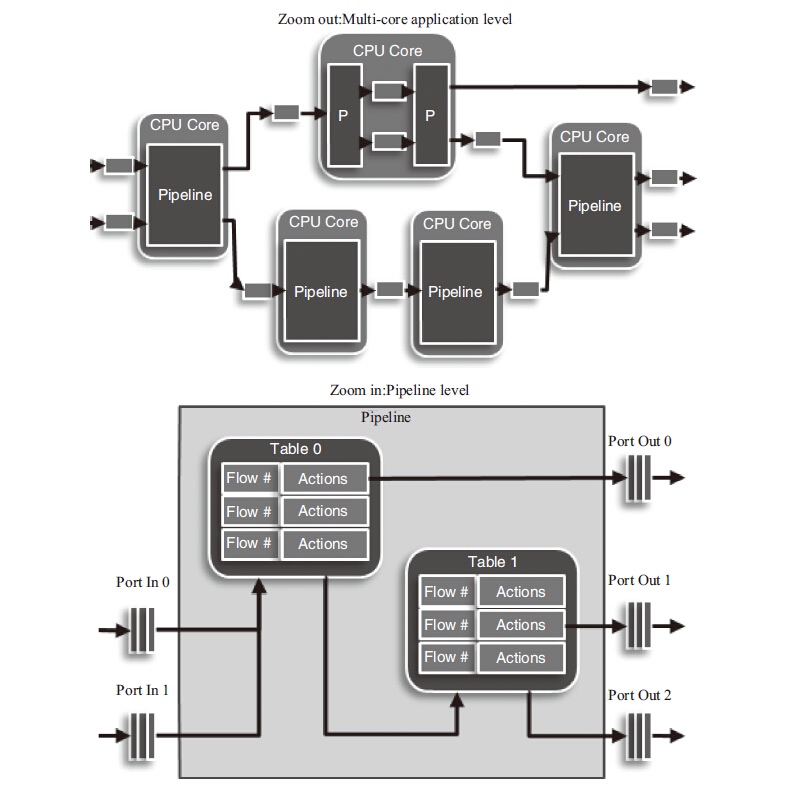
Zoom out的实例中包含了五个DPDK pipeline处理模块,每个pipeline作为一个特定功能的包处理模块。一个报文从进入到发送,会有两个不同的路径,上面的路径有三个模块(解析、分类、发送),下面的路径有四个模块(解析、查表、修改、发送)。Zoom in的图示中代表在查表的pipeline中有两张查找表,报文根据不同的条件可以通过一级表或两级表的查询从不同的端口发送出去。
DPDK的pipeline是由三大部分组成的:

现在DPDK支持的pipeline有以下几种:
Packet I/OFlow classificationFirewallRoutingMetering
转发算法
除了良好的转发框架之外,转发中很重要的一部分内容就是对于报文字段的匹配和识别,在DPDK中主要用到了精确匹配(Exact Match)算法和最长前缀匹配(Longest Prefix Matching,LPM)算法来进行报文的匹配从而获得相应的信息。
精确匹配主要需要解决两个问题:进行数据的签名(哈希),解决哈希的冲突问题,DPDK中主要支持CRC32和J hash。
最长前缀匹配(Longest Prefix Matching,LPM)算法是指在IP协议中被路由器用于在路由表中进行选择的一个算法。当前DPDK使用的LPM算法就利用内存的消耗来换取LPM查找的性能提升。当查找表条目的前缀长度小于24位时,只需要一次访存就能找到下一条,根据概率统计,这是占较大概率的,当前缀大于24位时,则需要两次访存,但是这种情况是小概率事件。
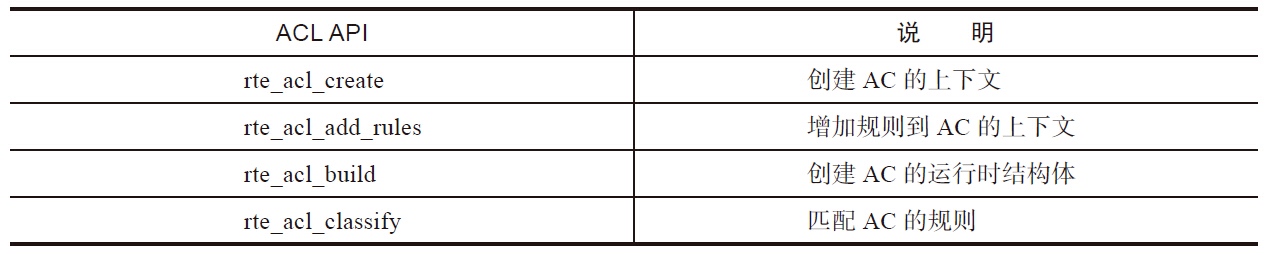
ACL库利用N元组的匹配规则去进行类型匹配,提供以下基本操作:
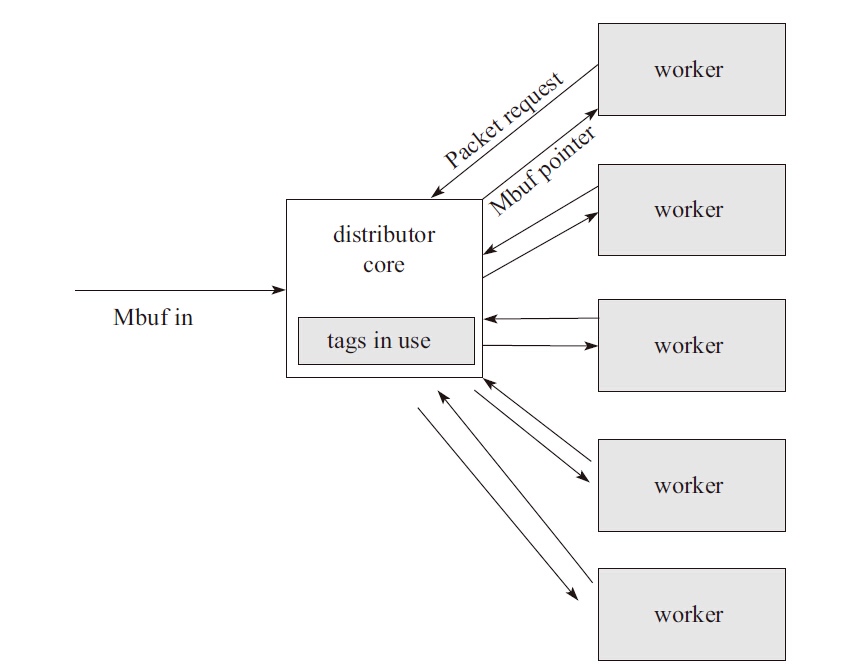
Packet distributor(报文分发)是DPDK提供给用户的一个用于包分发的API库,用于进行包分发。主要功能可以用下图进行描述