高性能服务端三要素
Tony Deng
Tony Deng
开发一个高性能的服务端需要些什么?
JavaGoScalaPHPC \ C++RubyNodeJSPythonSpringMartiniPlayYiiRORExpressDjango

别忘了,美女对于程序猿这个职业来说,基本上是非常非常稀奇的资源
我们今天不谈硬件,不谈操作系统,不评论开发语言及框架,不谈论算法
Cache
Asynchronous
Concurrent
Cache翻译成中文就是“缓存”,台湾的叫法是“快取”
其本质是将获取缓慢或计算缓慢的数据结果暂时存储起来,以便以后再次获取或计算同样地数据可以直接从存储中获得结果,从而可能提升性能的一种手段。
Cache其实最早应用在计算机的CPU中,有兴趣的同学可以自行Google
1+2+3+4+..+99+100=?
每隔一分钟进行上面的计算,你会怎么做?
(1/2)*100*(100+1),或者这样的公式100*(100+1)/2,(估计我需要一秒钟)计算机只会选择第一种方式来完成这个要求。
虽然上面的计算对于计算机来说,纸上小菜一碟,但是计算机往往面临的计算量比这个大的多得多
就像刚才那个场景一样,你会发现一些非常复杂的计算结果是可以复用的,而且把这个结果暂时存储在某个地方,查起来也很方便。(就像我们之前用小纸条来记录计算结果一样)
这个小纸条就是Cache
理解了Chace,我们可以来思考一些缓存的设计策略
不同的缓存策略和具体的业务场景关系非常大,制定缓存策略需要根据具体的情况来分析。
上面的1+2+3+...+100=5050这个结果是永远不会变化的,但是如果我们需要缓存今天的天气情况呢?或者需要缓存某一个列表,当这个列表发生变化了,我们应该怎么使用缓存呢?
既然提到了缓存的更新或清除,那么就涉及到缓存的更新策略。
假如我们要缓存某个分类的书籍列表,那么我们有些什么样的策略来进行缓存呢?
就是不在第一时间告知调用者结果,告诉他我已经收到这个任务了,我会处理,处理完了通知你结果。
如果你不是等不到结果就无法进行下去的话,你完全可以先去做别的事情。
你去一个咖啡店点了一杯咖啡,服务员告诉你需要15分钟才能做好,那在咖啡做好之前,你肯定不会一直在柜台前盯着服务员或咖啡师15分钟(如果美女可能会有例外...)。你肯定会干点别的,比如会看看手机或者和身边的朋友聊天......总之,你不会傻乎乎的等着。等到咖啡做好了,服务员会给你把咖啡送过来。
你在等待咖啡的过程中做了很多与这次购买咖啡无关的事情,这就是异步。你的大脑不必为一个漫长的过程卡住,可以继续其他的事情
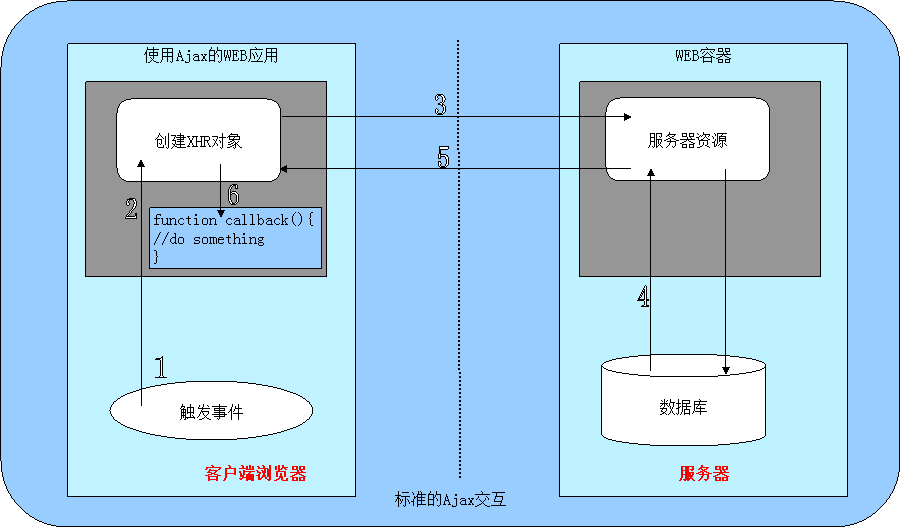
异步已经在现在各种编程语言和框架中都有相应地支持,比如AJAX,就是一种异步的手段。
AJAX使用回调的方式来支持异步,大致流程是:A交代给B一个任务,并且告知B “任务完成后继续执行哪段程序(往往包装成一个匿名的函数)”,B执行完任务后,执行这个匿名的方法,这样来完成异步过程。
在Javascript中大量的使用这种回调的异步方案,已经不再局限于一个缓慢的过程了,可以对于几乎所有的过程都采用异步处理。(基于Javascript的NodeJS更是将这种异步方案使用到极致)
生产者发送消息到消息队列中,消费者监听这个队列,当发现有消息之后,从队列取出消息,并作出相应处理,并把结果存储起来或者通过某种方式告知生产者。
异步再很多时候,可以运用现代化计算机CPU的多核特性和分布式计算特性,能显著的提升应用的性能,但是一定要注意一个前提就是:
异步任务的结果必须是主进程进行下一步操作所不依赖的,否则主进程必须等待,直到这个任务执行结束,拿到结果再进行下一步,这时就变成传统的同步计算了。
如果将一个任务拆分成多个更小的任务,同时来进行,这样是不是更快些呢?
现代的CPU往往具有多个核心,而且有些CPU也具有超线程能力,我们完全可以将一个任务拆成多个小得任务,交给CPU的多个核心,或者分布式计算系统的多个计算节点,就可以充分利用并行计算来提升性能。
你要拆分的各个小任务之间不要有相互依赖的关系。
有一批用户,我们需要计算他们的活跃度。
public List<Commit> getCommits(String objectId, String path, int offset, int maxCount) {
List<String> shas = getCommitsSha(this, objectId, path, offset, maxCount);
List<Commit> commits = new ArrayList<>();
if (shas != null) {
List<GetCommit> getCommits = new ArrayList<>();
for (String sha : shas) {
getCommits.add(new GetCommit(this, sha));
}
//声明一个自适应的线程池
ExecutorService executor = Executors.newFixedThreadPool(8);
List<Future<Commit>> futureList = null;
//并发的调用getCommit
futureList = executor.invokeAll(getCommits);
executor.shutdown();
for (Future<Commit> future : futureList) {
Commit commit = future.get();
commits.add(commit);
}
}
return commits;
}
利用Java的Cocurrent包来做并发循环,充分利用多核来尽快得到执行结果
//声明一个自适应的线程池
ExecutorService executor = Executors.newFixedThreadPool(8);
List<Future<Commit>> futureList = null;
//并发的调用getCommit
futureList = executor.invokeAll(getCommits);
executor.shutdown();
关于高性能服务端程序需要注意的点还有很多,这里只是简单介绍了Cahce(缓存)、Asynchronous(异步)、Concurrent(并行)三个利器。即便我介绍的也只是这三个利器的冰山一角,但是请相信,如果你理解了这三个东西,从和你关系思考服务端变成,会获得不少的收获。
这三者也是相辅相成的关系,很多时候都是配合着使用才能起到很好的效果。异步和并行在某种程度上是有重叠的,而我们经常使用异步的方式去主动构建缓存。