1. 什么是STRIDE威胁建模
计算机发明后不久,人脉就发现需要为这些信息系统处理威胁。早在1994年,NSA和DARPA就提出攻击树、威胁树等概念。1999年微软内部发表了《The threats to out products》的文章,为定义Windows全系列产品面临的安全威胁正式提出了STRIDE。随着2002年比尔.盖茨著名的《可信任计算备忘》发布,微软承诺改善软件产品的安全性,随即正式在SDL(安全开发生命周期)中采用了威胁建模。
研发团队的安全例行活动中,对于一些拥有重要数据资产、安全事件影响力大的系统除了要进行常规的渗透测试、黑白盒代码扫描以外,更应该系统定期开展威胁建模活动并对业务赋能。所以对于研发团队来说,引入先进的安全技术设计能力,构建全方位、多维度防御体系,是不懈追求的目标。
通过威胁建模,我们能够实现以下这些价值:
- 识别体系化的结构缺陷:大多数安全问题是设计缺陷问题,而不是安全性错误。威胁建模能帮助识别这些设计缺陷,从而减少风险敞口,指导安全测试,并降低因安全漏洞而造成的品牌损害或财务损失等可能性。
- 节约组织安全成本:通过对威胁进行建模,并在设计阶段建立安全性需求,降低安全设计缺陷导致的修复成本。在需求管理和威胁分析阶段,与业务开发团队高效互动,释放安全团队的专业能力,专注于高性价比的安全建设。
- 落地DevSecOps文化:通过威胁建模跑通开发和安全工具的流程集成,把风险管理嵌入产品的完整生命周期,从而推动形成完整的
DevSecOps工具链。 - 满足合规要求:威胁建模是国际安全行业通用的方法论,通过向管理层和监管机构提供产品的风险管理活动的完整记录,帮助团队遵守全球法律法规要求,包括
PCI DSS、GDPR、HIPAA、CSA STAR等。
STRIDE作为当前最流行的威胁建模方法,是值得研发团队引入的威胁建模的方法。STRIDE是以下英文的首字母缩写,把威胁分为6类,基本上涵盖了所有的威胁类型,帮助建模者对威胁进行建模。
S:Spoofing(假冒)T:Tampering(篡改)R:Repudiation(抵赖)I:Information Disclosure(信息泄露)D:Denial of Service(拒绝服务)E:Elevation of Privilege(权限提升)
2. STRIDE威胁建模整体流程
STRIDE威胁建模方法贯穿于整体风险分析流程,将安全需求分析和安全设计相互融合。STRIDE威胁建模不仅仅可以用于安全需求分析和设计,也可用于后续安全开发环节。
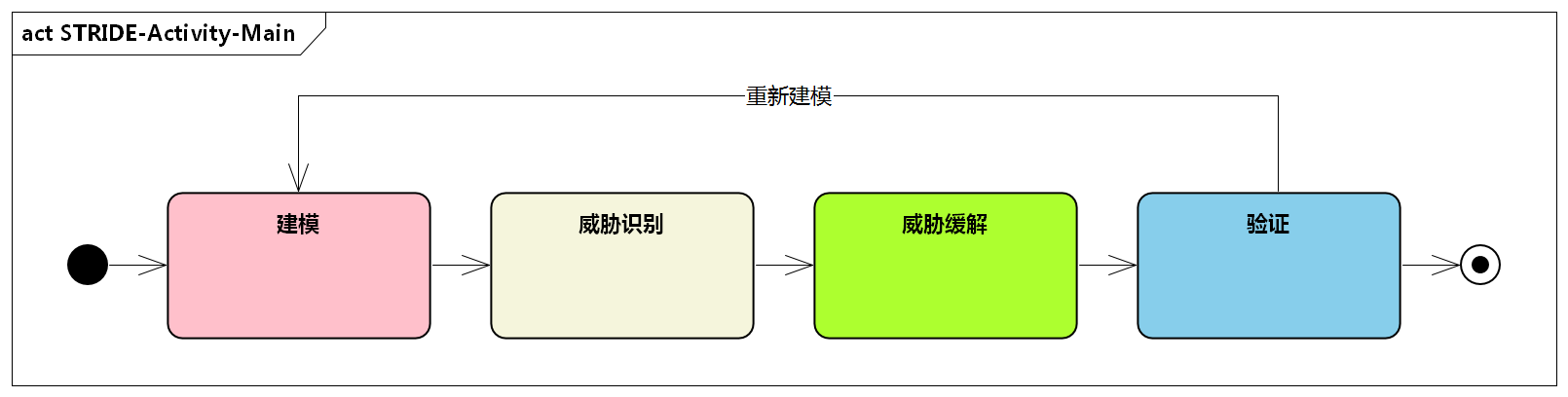
在威胁建模过程中起主导作用的是软件设计者、开发人员和测试人员。威胁建模的对象并不一定是一个完整的软件。根据需求的不同,建模对象可以是整个应用、安全和隐私相关的功能、跨信任边界的功能等等。
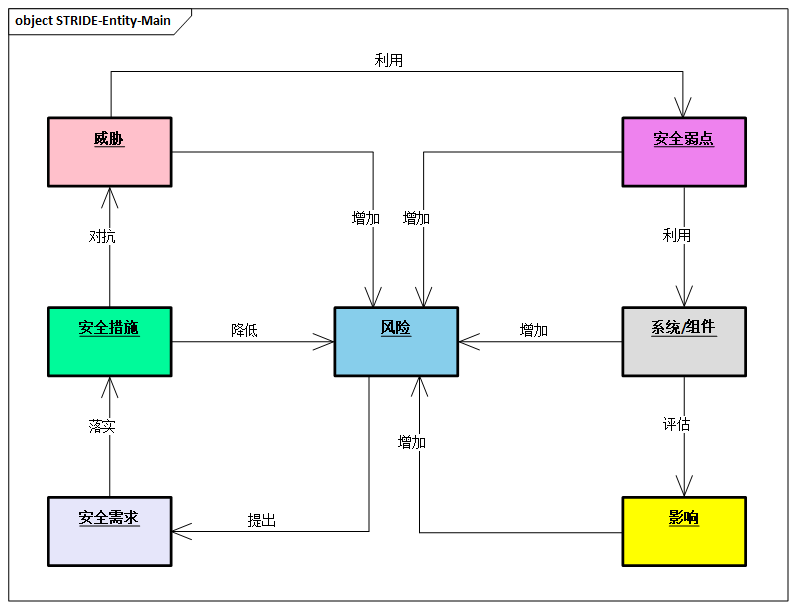
威胁建模的整体过程,本质上就是通过分析系统中的各个组件本身的安全弱点和影响,形成安全风险评估,同时基于安全风险提出相应的安全要求和采用相关的安全措施,缓解安全威胁,降低安全风险。
3. 威胁建模
建模是对软件进行抽象,数据流图、统一UML图表、泳道图和状态图等都可用于软件建模。接下来主要介绍数据流图建模过程。

数据流图建模过程的主要步骤包括:
- 定义应用场景:为了明确应用或系统的关键威胁场景,包括部署方式、配置信息、用户使用方式。
- 收集外部依赖:收集应用或系统所依赖的外部产品、功能或服务信息。典型外部依赖包括操作系统、数据库、Web服务器、应用服务器。
- 定义安全假设:采用来自其他功能组件所提供的安全服务假设,定义安全假设是为了对应用所依赖的系统环境做出准确的安全假设。
- 创建外部安全备注:为了让与产品相关的用户或其他应用的设计者都可以利用外部安全备注,辅助理解应用的安全边界,以及在使用应用时应如何保障安全不受侵害。
- 绘制数据流图:描述系统的一种方法,是威胁建模的重要产物,它使用易于理解的一种图形表示工具分析系统或应用可能面临的攻击。
其中绘制数据流图是建模过程的重点,其余步骤都是为绘制正确的数据流图做准备。
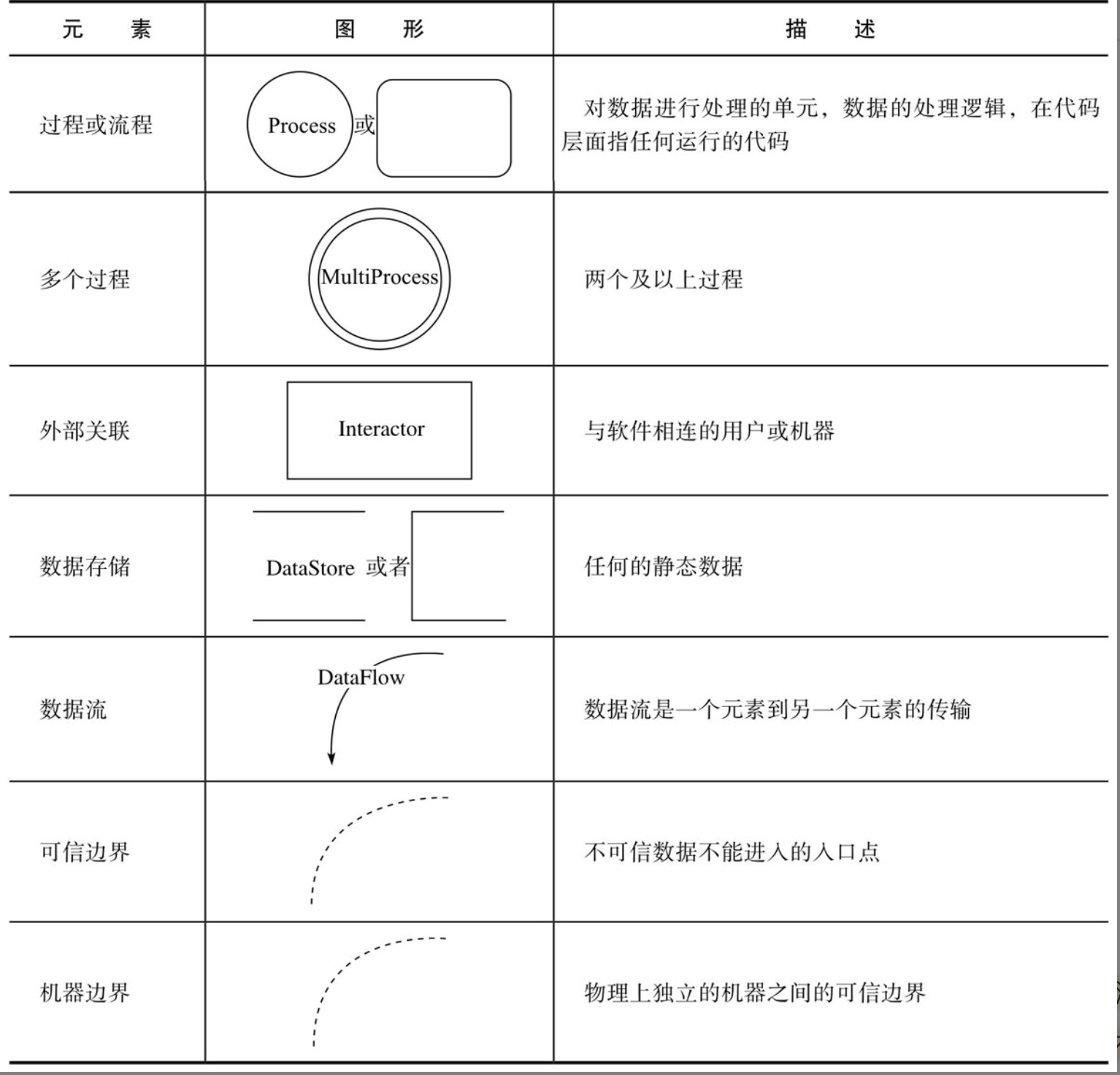
建模首先确定要分析的应用程序边界或作用范围,确定可信任部分与不可信任部分的界限。
在数据流图中创建和命名实体应遵循以下规则:
- 一个过程必须至少有一个数据流流入和一个数据流流出
- 所有的数据流都从某个过程开始,到某个过程结束
- 数据存储通过数据流与过程相连
- 数据存储不能直接连接,必须通过过程相连
3.1. High Level威胁建模
High Level你可以理解为系统上下文图(System Context Diagram),这一层级中细节并不重要,只显示系统概况。 重点应该放在人员(角色)和软件系统上,而不是技术,协议和其他低层级细节上,从而使非技术人员也能够看得懂。这个图也是明确需求的重要图示。这表示一个应用和其他系统的下辖有调用关系。不需要完整表示数据的流向,只要大致描述清楚系统的周边关系,不遗漏关键步骤。
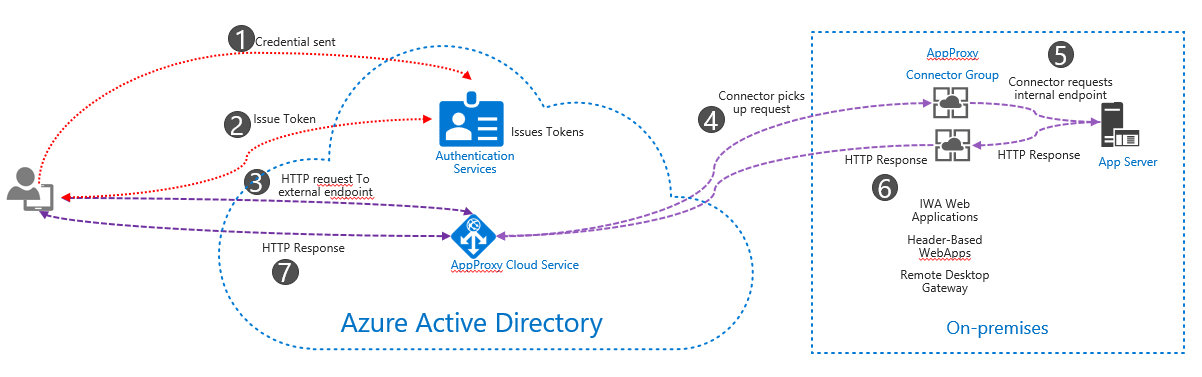
微软Azure的威胁建模的数据流图,有点是通过数字表示流程顺序
3.2. Low Level威胁建模
Low Level可以采用两种建模方式。
3.2.1. 应用图(Application Diagram)
应用是可单独运行/可部署的单元(例如,单独的进程空间)执行代码或存储数据。应用图显示了软件体系结构的高层结构以及如何分配职责。它还显示了主要的技术选择以及容器之间的通信方式。
一个应用包含多个服务,如果一个系统有多个子系统,应该对每个子系统都进行分析。通过威胁建模应该尝试了解整体情况,包含应用本身、数据库、交互、部署场景、云服务、接入的基础服务。
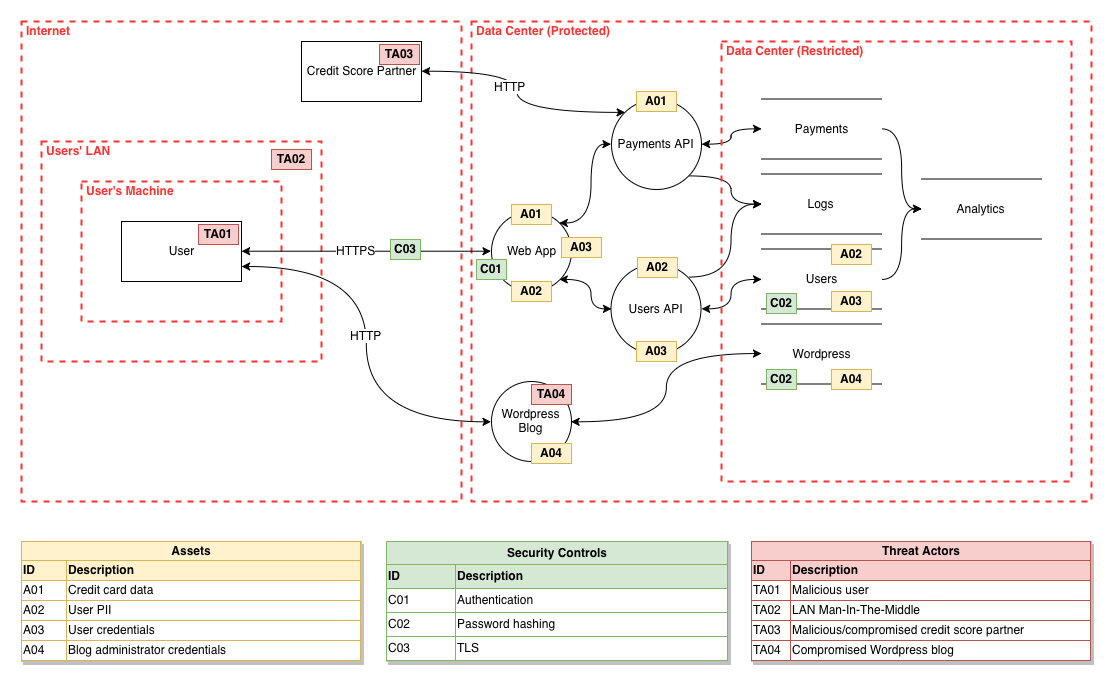
3.2.2. 服务图(Service Component diagram)
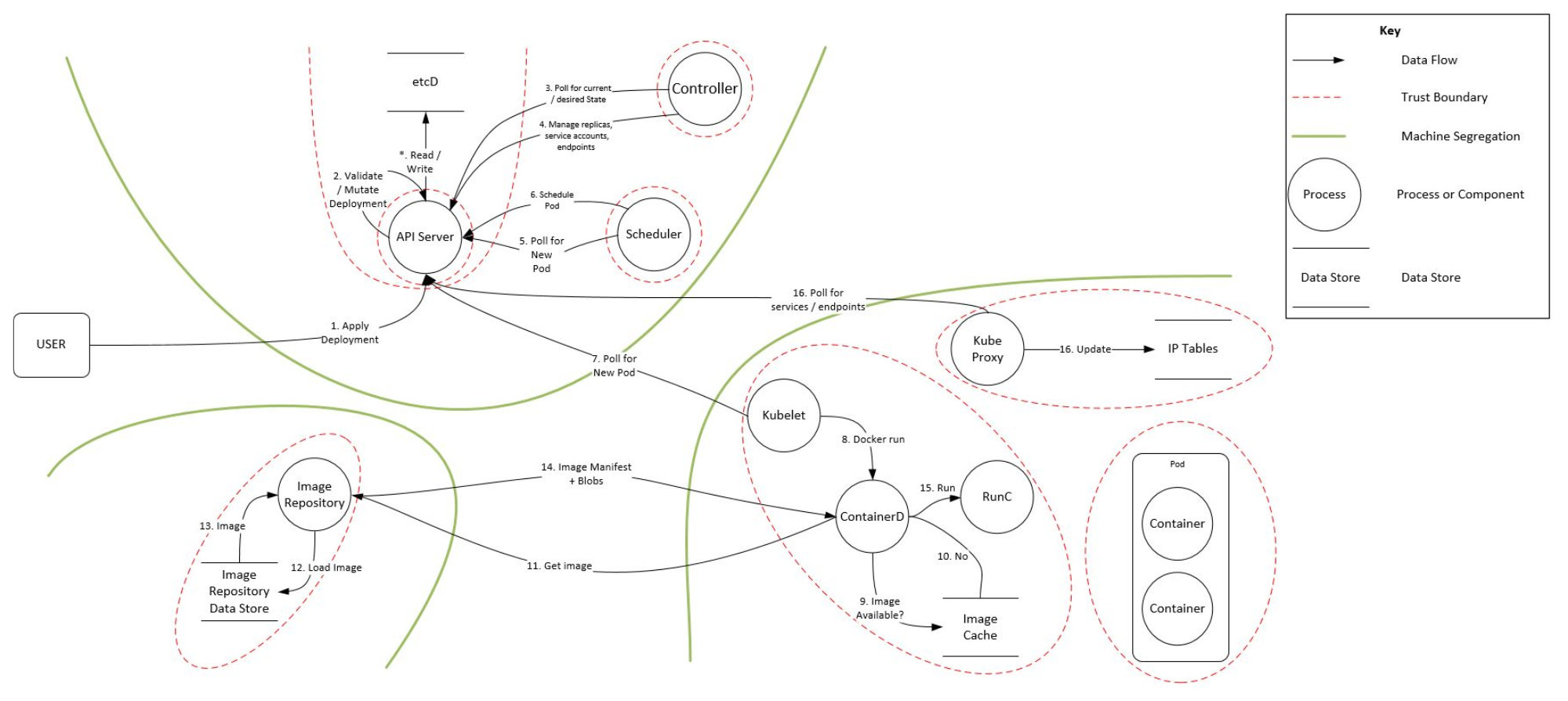
服务图显示了服务如何由多个“组件”组成,每个组件是什么,它们的职责以及技术/实现接口(API)或者细节。这个细粒度的分解是建模最大的工作量,为分解的各个通用组件创建的威胁模型结果可以复用在其他应用上。比如Kubernetes被分为Kube-Proxy、ETCD、Kubelet、Kube-APIServer、Scheduler、Container、Pods等。
4. 威胁识别
建模完成后,进入威胁识别过程。
威胁识别方法包括STRIDE方法、攻击树、攻击库等。主要关注STRIDE威胁识别方法。
该方法分析各个数据流及其关联的资产是否受到S、T、R、I、D、E威胁的影响,识别并记录这些威胁,然后使用DREAD方法对威胁进行量化分析,评估可能造成的危害程度。
4.1. STRIDE-per-Element模型
STRIDE-per-Element使得STRIDE更加规范,通过关注每一个元素的一系列威胁,可以更容易地找到威胁。
| 元素 | 交互 | S(假冒) | T(篡改) | R(抵赖) | I(信息泄露) | D(拒绝服务) | E(权限提升) |
|---|---|---|---|---|---|---|---|
| 外部实体(浏览器) | 外部交互实体将输入传入到过程 | * | * | * | |||
| 外部交互实体从进程得到输入 | * | ||||||
| 进程 | 进程有外来数据攒送至数据存储 | * | * | ||||
| 进程向另一个进程输出数据 | * | * | * | * | * | ||
| 进程向外部交互实体(代码)发送输出 | * | * | * | * | |||
| 进程向外部交互实体(人类)发送输出 | * | ||||||
| 进程有来自数据存储的输入数据流 | * | * | * | * | |||
| 进程有来自另一个进程的输入数据流 | * | * | * | * | |||
| 进程有来自外部交互实体的输入数据流 | * | * | * | ||||
| 数据流(命令/响应) | 跨越机器边界 | * | * | * | |||
| 数据存储(数据库) | 进程有输出数据流至数据存储 | * | * | * | * | ||
| 进程有来自数据存储的输入数据流 | * | * | * |
如何进行威胁识别,可以参考下面这个的例子,场景是租户通过第三方开放平台登录后通过微服务处理业务。
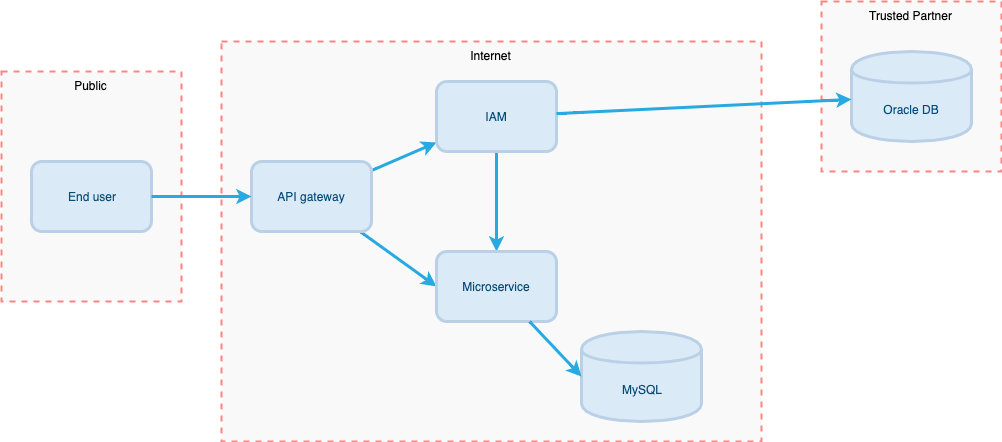
对于API网关,存在的威胁包括:
- 认证和授权
- 未强制HTTPS
- 缺失二次认证措施
- 日志和监控
- 缺失日志记录和审计模块
- 日志本地留存
对于IAM服务服务器,存在的威胁包括:
- 信息泄露:用户身份信息泄露
- 认证
- 暴力破解对外发送的管理平台Token
- 授权策略绕过
- 可用性
- 单机实例,误操作可导致宕机风险
对于MySQL服务,部分存在的威胁包括:
- 认证:攻击者获取凭据后可以直接访问、修改、删除业务数据
- 权限提升:攻击者可以从普通用户提升至Root,获取数据库完全控制权限
- 信息泄露:SQL注入导致所保存的业务数据泄露
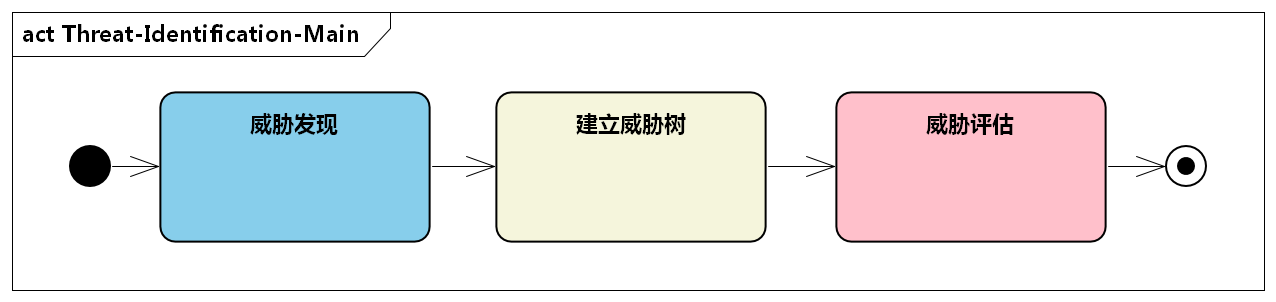
4.2. 威胁发现
使用STRIDE对威胁分类后,可以使用威胁树分析程序中的威胁和漏洞。
硬件领域常用“故障树”识别可能存在的故障模式,同样的方法也适用于描述软件安全问题。
威胁树起源于故障树,采用树形结构描述系统面临的威胁。
用根节点表示系统所面临威胁的抽象描述,逐层细化威胁的细节信息,直到用叶节点表示具体攻击方式。
威胁树描述了攻击者破坏各组件所经历的决策过程。
4.3. 威胁评估
建立威胁树后,就可以对威胁进行量化评估,评定其严重程度,可以使用DREAD方法来完成。
DREAD方法是以下单词的首字母缩写,分别从五个方面描述威胁的危害程度,每个方面危害程度的评分范围是1~10,10表示威胁造成的危害程度最大。
Damage potential(潜在破坏性): 用于衡量威胁可能造成的实际破坏程度,如10可以表示攻击者可能绕开所有安全限制,实际上能做任何事情;7~8表示攻击者能读取机密数据;6表示攻击者能使服务器暂时不可用。Reproducibility(再现性):即衡量威胁可能造成的实际破坏程度,如10可以表示攻击者可能绕开所有安全限制,实际上能做任何事情;7~8表示攻击者能读取机密数据;6表示攻击者能使服务器暂时不可用。Exploitability(可利用性):指的是进行一次攻击需要的努力和专业知识。如果一个普通用户使用一台家庭计算机就能实施攻击,可以评定为10。如果需要动用大量人力物力才能进行一次攻击,那么可利用性评为1。Affected users(受影响用户):指如果威胁被利用并成功攻击,有多少用户会受到影响,10指所有用户都会受到影响,1~9表示受影响用户的百分比。Discoverability(可发现性):指如果威胁被利用并成功攻击,有多少用户会受到影响,10指所有用户都会受到影响,1~9表示受影响用户的百分比。
依据公式 *“风险=受攻击概率危害程度”** ,可以计算出五个风险值,然后对五个风险值求平均数,平均数越大,则威胁对系统造成的风险就越大。假设受攻击概率为100%,最高风险值是10。
5. 威胁缓解
识别威胁后,就可以对已经暴露的威胁进行缓解。
不同风险等级的威胁可以采取不同处理策略:
- 低风险安全威胁,可以保持现状
- 潜在的用户危险操作,要及时提醒
- 可以缓解的威胁,要采取加密、认证等技术缓解措施
- 风险过高并且难以实施缓解措施的威胁,可以考虑删除/关闭相应功能
5.1. 确立缓解顺序
威胁的缓解顺序在整体设计上要有条理性和层次性。
例如,对闯入家里进行威胁建模。考虑窗户是受攻击面,那么威胁包括打破窗户进入和打开窗户进入的人。
打破窗户可以通过使用强化玻璃来阻止,这就是一阶缓解措施;
打破玻璃威胁也可以通过警报来解决,这就是二阶防御措施。
如果切掉电源,警报失效,为了解决这个三阶威胁,系统设计人员可以添加更多的防御措施,例如,警报包含剪断电源警报,防御者可以添加电池、手机或者其他无线设备。
虽然具体威胁所采用的缓解措施截然不同,但是一定要有全面的缓解措施,因为一旦底层的措施出现纰漏,无论高层措施多么完善,攻击者依然可以以很低成本进行攻击。
5.2. 常用缓解方法
不同安全威胁需要采用不同的技术缓解方法。
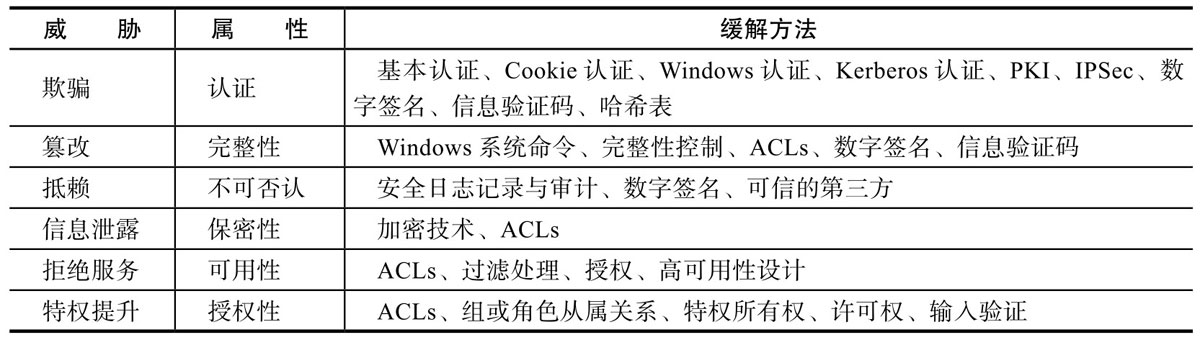
上面是几种常用的缓解方法,包括认证、授权、防篡改和增强保密性的技术。
在建模、识别及缓解威胁的过程中,必须记录每一个操作的详细信息,以便于理解和管理。
6. 威胁验证
验证是为了确保威胁模型准确反映应用程序的潜在安全问题,验证的内容包括:
- 威胁模型
- 列举的威胁
- 缓解措施和假设
验证威胁是说明列举出的威胁如何进行攻击,攻击的内容及影响。
如果验证威胁出现问题,说明威胁没有被正确识别,可能需要重新建模。
此外,还要分析威胁列举是否全面,如与可信边界接触的元素都可能被污染,这些元素都应该考虑STRIDE威胁。
如果建模时得到的威胁不够全面,需要进一步补充。
验证缓解措施是指检验缓解措施能否有效降低威胁影响,是否正确实施,每个威胁是否都有相应缓解措施。一旦措施无效,或者低效,必须重新选择缓解方法。如果没有正确实施,应该发出警告,确保缓解措施的有效性。
危害较为严重的威胁都要有缓解措施,以减少危害程度。
验证假设是为了判断假设是否正确,只有假设合理,才能保证在假设条件下进行的操作是合理的。