
刚开始学习Rust时,我觉得它的模块机制难以理解。后来才明白是自己想多了,Rust模块其实就是命名空间,仅此而已。它的crate倒更像是其他语言的模块。
从Rust编译来理解
Rust编译器只接受一个.rs文件作为输入,并且只生成一个crate。这一点要牢记。
生成的crate分两种,源文件中有main函数会生成可执行文件,无main函数则生成库。
// hello.rs |
运行rustc hello.rs会生成同名的可执行文件hello
// hello.rs |
使用--crate-type=lib参数编译成库,如果没有pub关键字,则会有如下提示。
$ rustc hello.rs --crate-type=lib |
运行rustc hello.rs --crate-type=lib会生成同名的库libhello.rlib。函数前面多了一个关键词pub,如果不加的话编译器会告警,说“你这个库啥public的东西都没有,让别人用毛啊”。恩,Rust编译器还是很贴心的。
引入命名空间
Rust的模块就是命名空间,用关键词mod表示。它的作用是把一个crate的代码划分成可管理的部分。每一个crate都有一个顶层的匿名根命名空间, 根空间下面的命名空间可以任意嵌套,这样构成一个树形结构。
假设我们接到一个项目,制作一个包含各国语言日常用语的程序库。
- 首先,这个库应该按语种名组织,中俄日美等都给他们划分出一个模块
- 日常用语有很多,如果我们想把代码组织得更清晰一点,还可以按照使用场景再划分一次,比如有用于问候的(“你好”、“吃了么”),有用于离别的(“再见”,“天下谁人不识君”)
// phrases.rs |
运行rustc phrases.rs --crate-type=lib得到一个程序库,其模块树形图如下:
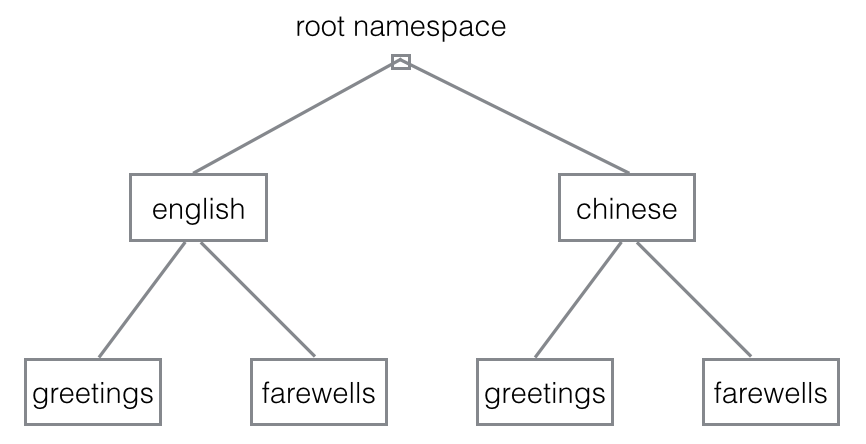
// 朋友分别,请用下面两句 |
打散命名空间
好,我们已经学会使用命名空间了,但是所有的代码都在phrases.rs这个文件中,这在正式开发中是不能容忍的。还好Rust编译器给我提供了一个将单个文件拆成多个文件的机制。
我们把phrases.rs改成如下,编译器每次看到未定义的mod语句时会去找相应地文件,填充到这个位置。我们可以理解为,编译器把若干个文件合并成一个文件。
// phrases.rs |
// english/mod.rs |
// english/farewells.rs |
chinese模块我就不写了,类比english模块。
提升命名空间
编译器的机制决定,除了mod.rs外,每一个文件和目录都是一个模块。有时候我们只是想分拆文件,但是不想添加新的模块。编译器像个暴君一样,说:“在我的国家,不允许干这样的事儿。”
不过也不是没有变通的机制,pub use就是惯用手法。
// english/mod.rs |
english模块添加了两个pub use语句后,两个问候函数就提升到english空间中去了,我们可以用phrases::english::hello()来代替phrases::english::greetings::hello()。
总结
Rust Module就是命名空间,没别的意思Rust编译器只接受一个源文件,输出一个crate- 每一个
crate都有一个匿名的根命名空间,命名空间可以无限嵌套 - “
mod mod-name { ... }“ 将大括号中的代码置于命名空间mod-name之下 - “
use mod-name1::mod-name2;"可以打开命名空间,减少无休止的::操作符 - “
mod mod-name;“ 可以指导编译器将多个文件组装成一个文件 - “
pub use mod-nam1::mod-name2::item-name;“ 语句可以将mod-name2下的item-name提升到这条语句所在的空间,item-name通常是函数或者结构体。Rust社区通常用这个方法来缩短库API的命名空间深度 - 编译器规定
use语句一定要在mod语句之前