本文来自团队中学科同学的分享
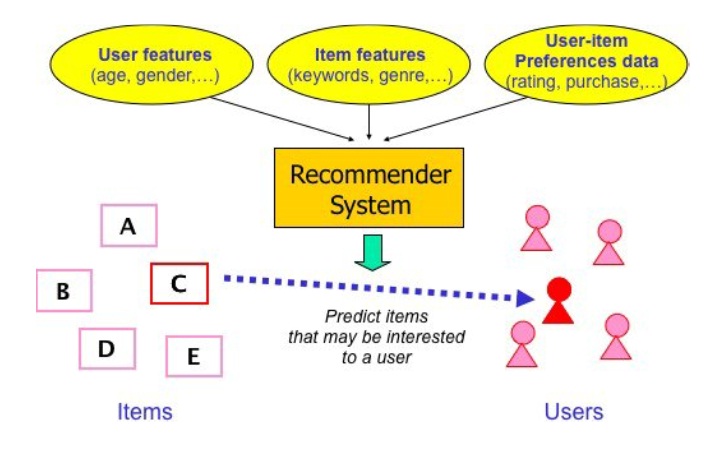
场景
根据用户行为分析用户偏好,将不同偏好的用户进行群组划分和“商品”推荐
常见于网上购物,点评,游戏市场等
SPARK实现
- 读取原始数据
- 格式化成RDD数据:用户,产品,评分
- 矩阵SVD分解
- 计算用户相似度
- 根据加权评分计算推荐结果
代码
读取文件
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = sc.textFile("...");格式化数据
JavaRDD<Vector> simple = lines.map(line -> {
...
return Vectors.dense(values);
});SVD分解
RowMatrix mat = new RowMatrix(simple.rdd());
SingularValueDecomposition<RowMatrix, Matrix> svd = mat.computeSVD(2, true, 1.0E-9d);计算用户相似度
double dist = Vectors.sqdist(v1._1.vector(), v1._2.vector());
原理
| Table | 小时代1 | 小时代2 | 小时代3 | 小时代4 | … | 疾病N |
|---|---|---|---|---|---|---|
| 用户1 | 5 | 0 | 5 | 0 | ||
| 用户2 | 5 | 2 | 4 | 0 | ||
| 用户3 | 3 | 1 | 3 | 0 | ||
| 用户4 | 1 | 5 | 1 | 4 | ||
| … | ||||||
| 患者N |



