让面试者描述一下缓存算法,以及经典的缓存算法LRU的实现,是我在面试过程中经常会问到的题目。
能够当场说出LRU算法实现思路的人基本没有,甚至不少人都无法说清楚LRU是一个实现什么功能的算法。(现在肯专心研究数据结构和算法的人不多了)
那我们今天就说一下LRU算法,分两点来说一下。
- LRU算法是要做什么?
- 我们有没有什么简单的方法来实现LRU算法?
先说说第一点,LRU算法是要做什么?
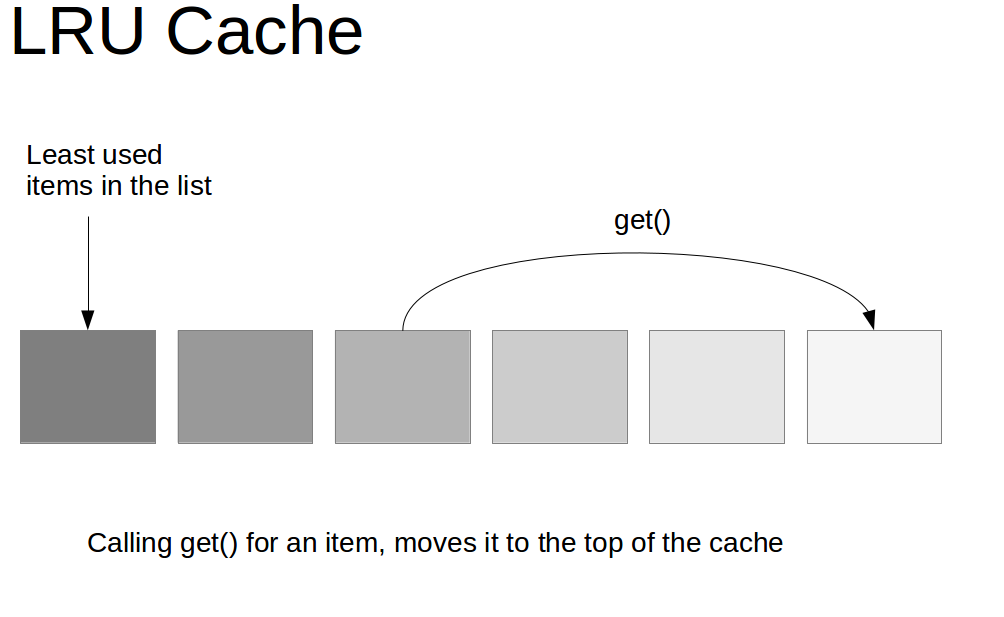
其实解释起来很简单,LRU就是Least Recently Used的缩写,翻译过来就是**“最近最少使用”**。也就是说LRU算法会将最近最少用的缓存移除,让给最新使用的缓存。而往往最常读取的,也就是读取次数最多的,所以利用好LRU算法,我们能够提供对热点数据的缓存效率,能够提高缓存服务的内存使用率。
那如何来实现呢?
我们先来梳理一下,需要实现几个什么功能?
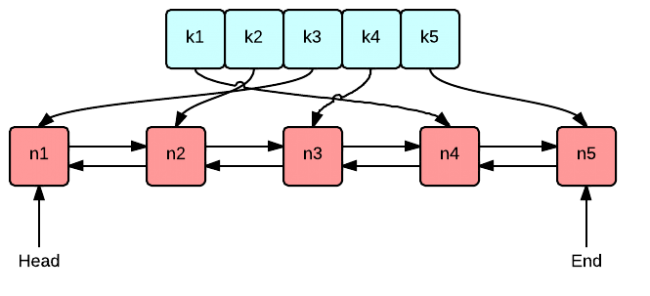
- 限制缓存大小
- 查询出最近最晚用的缓存
- 给最近最少用的缓存做一个标识
其实,实现的思路非常简单,就像下面这张图种描述的一样。
今天我就利用Java的LinkedHashMap用非常简单的代码来实现基于LRU算法的Cache功能。
实现代码如下,加上import语句、注释和空行,也才不到20行的代码,就能够实现一个LRU算法的Cache:
import java.util.LinkedHashMap; |
测试代码:
import org.junit.Ignore; |